

Today we are excited to introduce the new feature of Geek ElasticSearch that enables to take full advantage of Elasticsearch’s capabilities.
In the new version 4.7.0 of Geek ElasticSearch, we have added a feature that enables you to update index settings. This helps you to configure the analyzer for the index, to change Character Filters, Tokenizer and Token Filters to meet the requirements of search that your website needs.
In the Control Panel of Geek ElasticSearch, you will find a new page “Index Settings”. In this page, the left column shows the current settings information of the index, the right column displays the form where you can add and put settings to your index.
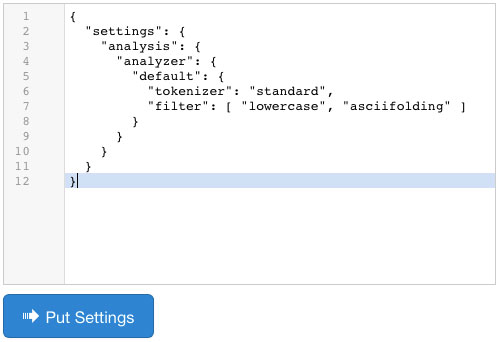
You have to add settings in JSON format from the code editor, then click on the "Put Settings" button to send an update request of index settings. If your settings are valid and updated successfully, you will see the new updated settings on the left column.
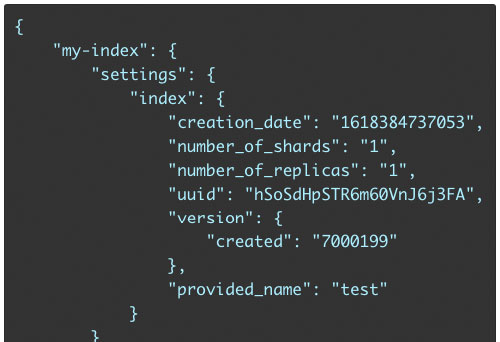
This is an advanced feature, in order to use this feature, we assume that you have basic knowledge of configuring Elasticsearch. So if you have no idea how to use this feature, please do not put any update settings to avoid unexpecting errors.
Some example of analyzers
Elasticsearch provides some built-in analyzers for your reference. You can copy sample settings from the guide pages to update your index settings.
Please NOTE that Geek ElasticSearch does not support specify analyzer for the fields, it uses default analyzer for all text fields by default. So instead of creating custom analyzers, you need to update the default analyzer, and new settings will be applied to all fields without a need for updating mapping.
For more details, when you copy settings from the Elasticsearch guide page, you need to replace the name of the custom analyzer to “default”. For example if the sample settings code is:
"analyzer": {
"rebuilt_arabic": {
...
}
}
You need to replace the name of analyzer that is "rebuilt_arabic" to "default" as follows:
"analyzer": {
"default": {
...
}
}
Language Analyzers
Language Analyzers are a set of analyzers aimed to analyzing specific language texts. The following types are supported: arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english, estonian, finnish, french, galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, persian, portuguese, romanian, russian, sorani, spanish, swedish, turkish, thai.
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lang-analyzer.html
ASCII Folding Token Filter
This Token Filter converts alphabetic, numeric, and symbolic characters that are not in the Basic Latin Unicode block (first 127 ASCII characters) to their ASCII equivalent, if one exists. For example, the filter changes à to a.
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-asciifolding-tokenfilter.html
This means that you can search accent-insensitive, for example if the document contains the text:
Vous êtes le Phénix des hôtes de ces bois.
Then you can use searchwords below to find it:
etes, Phenix, hotes
You can use the settings below to enable this feature:
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"tokenizer": "standard",
"filter": [ "asciifolding" ]
}
}
}
}
}
Lowercase token filter
The Token Filter changes token text to lowercase. This will enable the implementation of incase-sensitive search
For example, you can use the lowercase filter to change THE Lazy DoG to the lazy dog.
In addition to the default filter, the lowercase token filter provides access to Lucene’s language-specific lowercase filters for Greek, Irish, and Turkish.
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lowercase-tokenfilter.html
You can use the settings below to enable this feature:
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"tokenizer": "standard",
"filter": [ "lowercase" ]
}
}
}
}
}
You can also use many token filters together as follows:
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"tokenizer": "standard",
"filter": [ "lowercase", "asciifolding" ]
}
}
}
}
}
NOTE:
After the index settings updated successfully, You might need to re-index data to get new changes applied in documents.
IMPORTANT NOTE:
Configuring Elasticsearch is out of our support scope. So, you need to update your index settings by yourself.
If you need us for this help, please submit a request for Elasticsearch - installation service to
Some other new features and improvements
This version also comes with some new features and improvements as follows:
- New. Supports EasySocial 4.0 beta.
- New. Supports indexing EasySocial Marketplace items.
- Update. Plugin indexes articles to add new setting that enables users to select which field will be displayed for author name (username or real name)
- Improved. Plugin indexes Hikashop products to generate correct urls by category, improve performance of indexing process, filter by any categories that product assigned to.
- Improved. Plugin indexes Hikashop categories to generate correct urls by category.
- Fixed. The variables in the search results template cause error in the browser console.